1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/v2transapi'
headers = {
'cookie': 'REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1;
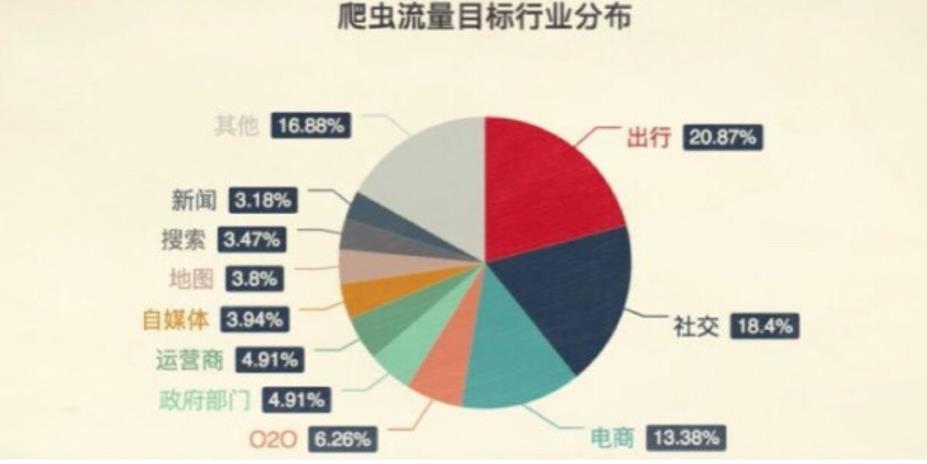
9.ajax的get请求
案例:豆瓣电影
SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; PSTM=1537097513;
BIDUPSID=D96F9A49A8630C54630DD60CE082A55C; BAIDUID=0814C35D13AE23F5EAFA8E0B24D9B436:FG=1;
to_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22
%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D;
from_lang_often=%5B%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%
22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598;
delPer=0; H_PS_PSSID=1424_21115_29522_29519_29099_29568_28835_29220_26350; PSINO=2; locale=zh;
Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1563000604,1563334706,1565592510;
Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1565592510;
yjs_js_security_passport=2379b52646498f3b5d216e6b21c6f1c7bf00f062_1565592544_js',
aldtype=16047&query=&keyfrom=baidu&smartresult=dict&lang=auto2zh',
# 'sec‐fetch‐mode': 'cors',
# 'sec‐fetch‐site': 'same‐origin',
# 'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/76.0.3809.100 Safari/537.36',
# 'x‐requested‐with': 'XMLHttpRequest',
}
data = {
'from': 'en',
'to': 'zh',
'query': 'you',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '269482.65435',
'token': '2e0f1cb44414248f3a2b49fbad28bbd5',
}
#参数的编码
data = urllib.parse.urlencode(data).encode('utf‐8')
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers,data=data)
response = urllib.request.urlopen(request)
# 请求之后返回的所有的数据
content = response.read().decode('utf‐8')
import json
# loads将字符串转换为python对象
obj = json.loads(content)
# python对象转换为json字符串 ensure_ascii=False 忽略字符集编码
s = json.dumps(obj,ensure_ascii=False)
print(s)
|