Tesseract.js将图像OCR转换带给浏览器
本文最后更新于:2024年3月20日 中午
前言
Tesseract.js将图像OCR转换带给浏览器
OCR转换仍然不是完美的,但是在过去几年中有了很大的改进。 领先的是目前以_C ++_开源的Tesseract 翻译引擎 。
尽管这是一个令人难以置信的库,但是它仅限于软件。 值得庆幸的是,有人将Tesseract移植到JavaScript中,称为Tesseract.js 。 它支持多达60种语言 ,虽然它虽然不完美,但是却做得很好。
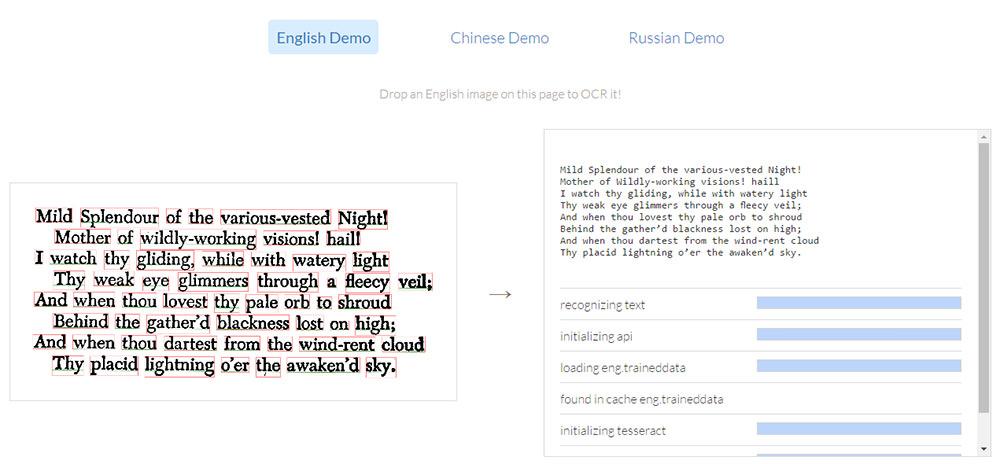
安装和设置很容易,您可以在页面上定位任何图像元素并运行Tesseract.recognize()函数。 这可以拍摄任何类型的图像,并且会在浏览器中自动进行自动压缩和转换 。
您可能会变得更加复杂,但是美丽之处在于, 如何使用一行代码即可运行OCR 。
如果您想观看现场演示,请查看Tesseract.js登陆页面 。 这在浏览器中可以正常工作,您可以在其中拖放任何扫描的文本图像以获得自动OCR翻译 。
您还可以通过GitHub页面在本地下载此示例,也可以通过直接从CDN包含Tesseract.js脚本来构建自己的应用程序。
最简单的代码示例如下所示,其中myImage是对HTML图像元素的直接引用:
1 | |
无论哪种方式,该库对于在Web上使用OCR都非常有用。 它远非完美,但对于想要动态页内OCR功能的Web开发人员来说,它也是最佳资源 。
要了解更多信息,请访问Tesseract.js GitHub页面 ,您可以在此处查看实时演示并浏览在线文档。
从具有GT文本的图像中复制和提取文本[Quicktip]
当您处理涉及图像的任务时,有时会出现文本或引号
从具有GT文本的图像中复制和提取文本
使用AdaptiveBackgrounds.js从图像到背景输入主要颜色
当在Web上展示某些东西时,一些开发人员通常会很难决定哪些背景
使用AdaptiveBackgrounds.js从图像到背景输入主要颜色
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!